Documentation Index
Fetch the complete documentation index at: https://docs.amplication.com/llms.txt
Use this file to discover all available pages before exploring further.
This page explains the technical details of Prisma schema conversion within
Amplication. For a practical guide on uploading your schema, see How to
Upload Schema.
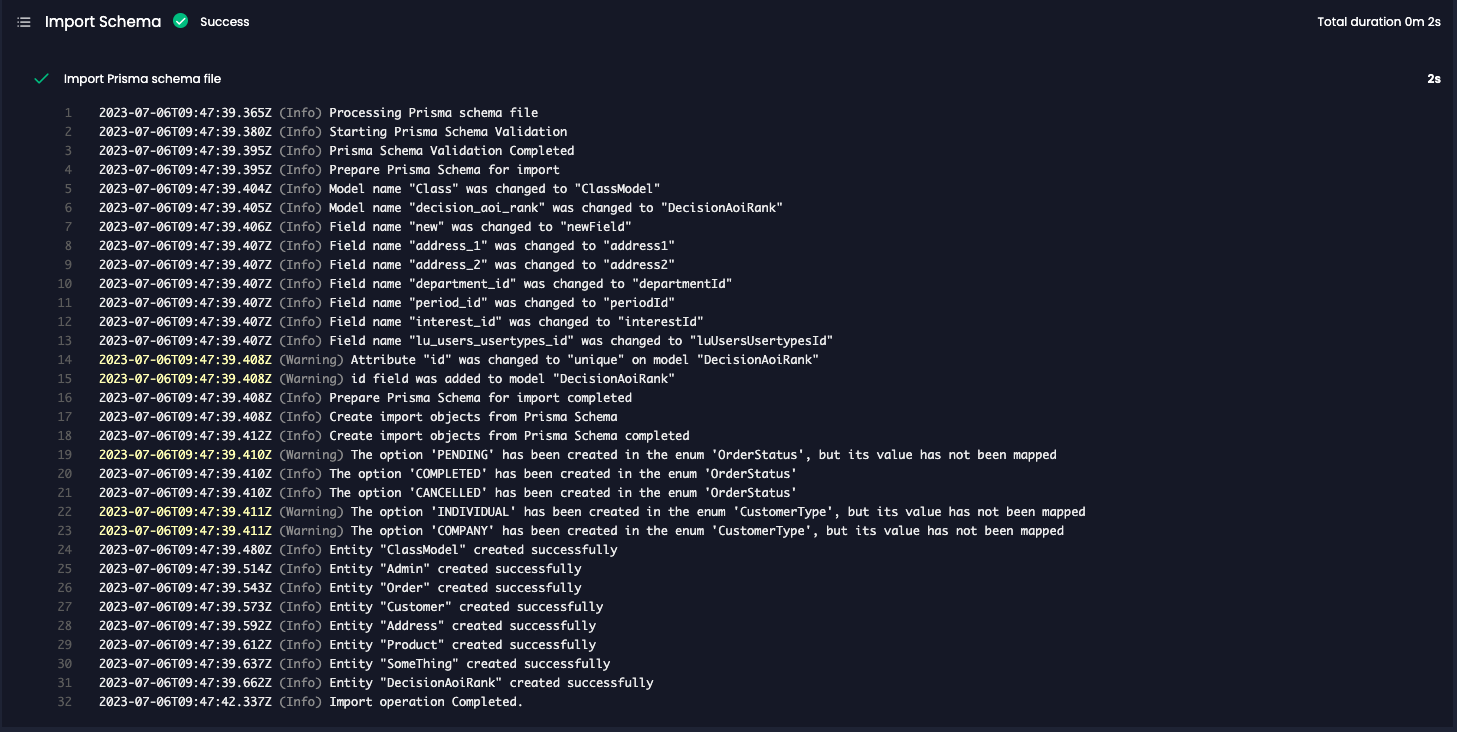
The 3-Step Conversion Process
During the schema upload, you’ll see logs detailing a three-phase conversion process:Validate: Ensuring Schema Integrity
The first step validates the syntax and structure of your
schema.prisma file against Prisma’s conventions. This ensures your schema is well-formed and ready for conversion. Crucially, it also checks for the presence of models – the building blocks of your services. Without models, the conversion process cannot proceed, ensuring a valid starting point.Prepare: Aligning with Amplication's Standards
The preparation phase standardizes your schema, applying five key transformations to ensure consistency and maintainability across all services generated by Amplication. This step is critical for platform teams aiming to enforce organizational standards and reduce technical drift.These transformations include:
- Model Names: Standardizing to PascalCase, singular, and no underscores.
- Field Names: Standardizing to camelCase and no underscores.
- Field Types: Ensuring consistent type references between models.
- Model IDs: Simplifying primary key definitions for clarity and consistency.
- Model ID Field: Guaranteeing a standardized
idfield for each entity.
Convert: Optimizing Data Types for Amplication
In the final conversion step, Prisma’s data types are mapped to Amplication’s internal data types. This ensures optimal performance and functionality within Amplication’s service generation framework. This mapping includes handling specific DateTime attributes for
CreatedAt and UpdatedAt fields, and translating Prisma’s type system to Amplication’s more abstract types like Lookup for relations and OptionSet for Enums.This step ensures that your database schema is not just imported, but intelligently adapted to Amplication’s architecture, maximizing efficiency and developer experience.Step 1: Validate - First Pass Schema Check
This step acts as an initial quality gate, confirming that yourschema.prisma is syntactically correct and contains the essential elements – models – necessary for Amplication to build upon. This quick check prevents wasted time and ensures the conversion process begins with a valid schema.
Step 2: Prepare - Standardizing for Consistency and Maintainability
This phase is where Amplication’s conversion happens. By applying these five operations, Amplication ensures that all generated services adhere to consistent naming conventions and structural patterns.Model Names: PascalCase, Singular, No Underscores
Model Names: PascalCase, Singular, No Underscores
Amplication enforces PascalCase, singular, and underscore-free naming conventions for models. This standardization is vital for code readability and maintainability, especially across large teams and numerous services.To maintain database compatibility and prevent data loss, Amplication intelligently uses Prisma’s Example:This ensures that while your Amplication service code uses
@@map attribute.
If your original model name deviates from Amplication’s conventions, @@map is automatically added, preserving the original database table name while using the standardized name within Amplication.If you have already used
@@map attributes in your schema, Amplication
respects your existing mappings and does not overwrite them.schema.prisma
CourseRating, the underlying database table remains course_rating, preventing any disruption to existing data or systems.Field Names: camelCase, No Underscores
Field Names: camelCase, No Underscores
Similar to model names, field names are standardized to camelCase and must be underscore-free. This consistency improves code readability and reduces cognitive load for developers working across different services.Just like with model names, Amplication uses Prisma’s Example:Here,
@map attribute to preserve your original database column names when necessary. This ensures seamless integration with existing databases and prevents unexpected data mapping issues.Existing
@map attributes on fields are also respected and not overwritten
during this process.schema.prisma
item_price is converted to itemPrice in your Amplication service, while the @map("item_price") attribute ensures the database column remains item_price.Field Types: Ensuring Model Relationships
Field Types: Ensuring Model Relationships
This operation focuses on ensuring that field types accurately reflect relationships between models. When you import a schema, especially from an introspected database, Prisma might use generic model names in relation fields. Amplication refines these to use the standardized, PascalCase model names established in the previous step.Example:Here,
schema.prisma
products and orders are corrected to Product and Order respectively, ensuring the relationship is clearly defined and consistent with Amplication’s model naming standards.Model IDs: Simplifying Primary Keys
Model IDs: Simplifying Primary Keys
Amplication standardizes the way primary keys are defined in your schema. It simplifies the This operation performs several key transformations:This ensures a consistent and predictable ID structure across all entities in Amplication.
@@id attribute, which in Prisma can define composite IDs, to focus on single-field primary keys, which aligns with Amplication’s entity structure.Composite IDs (
@@id([field1, field2])) are currently not fully supported in
Amplication.@@id([field])is converted to@@unique([field]). The original@@idis replaced with a@@uniqueconstraint to maintain uniqueness in the database.- The field originally designated as the primary key via
@@idnow becomes the actual ID field within Amplication. The@idattribute is added to this field. - If the field lacks a
@default()attribute (likecuid()for String IDs orautoincrement()for Int IDs), Amplication adds one based on the field’s type. This ensures every entity has a properly configured default ID generation strategy. - If the primary key field isn’t named “id”, it’s renamed to “id”, and a
@mapattribute is added to preserve the original field name in the database. - Finally, the
@@uniqueattribute is updated to reference the new “id” field:@@unique([originalFieldName])becomes@@unique([id]).
schema.prisma
Model ID Field: Ensuring a Standard 'id' Field
Model ID Field: Ensuring a Standard 'id' Field
The final preparation step guarantees that every model has a standardized This operation ensures that every Amplication entity has a clearly defined and consistently named
id field. This is a fundamental principle in Amplication, ensuring consistent entity identification across your services.This operation handles two main scenarios:- Non-ID fields named ‘id’: If a field is named
idbut isn’t an ID field (doesn’t have the@idattribute), it’s renamed to${modelName}Idto avoid naming conflicts with the actual ID field that Amplication will ensure exists. A@mapattribute is added to preserve the original name in the database. - ID fields with different names: If an ID field (with the
@idattribute) has a name other thanid, it’s renamed toid. Again, a@mapattribute is used to maintain the original field name in the database.
schema.prisma
id field, simplifying data access and relationships within your services.Step 3: Convert - Mapping Prisma Types to Amplication Data Types
The final conversion step maps Prisma’s data types to Amplication’s internal data types, optimizing them for service generation and functionality within the Amplication ecosystem. This step ensures that your data is represented in a way that best leverages Amplication’s features and capabilities. Here’s a table summarizing the Prisma to Amplication data type conversions:| Prisma | Amplication | Description |
|---|---|---|
String (ID) | Id | Converts ID fields with String type to Amplication Id type, defaulting to cuid() for ID generation. |
Int (ID) | Id (autoincrement) | Converts ID fields with Int type to Amplication Id type, using autoincrement() for ID generation. |
Boolean | Boolean | Direct mapping for Boolean types. |
DateTime (@default(now())) | CreatedAt | DateTime fields with @default(now()) are converted to Amplication’s specialized CreatedAt type. |
DateTime (@updatedAt) | UpdatedAt | DateTime fields with @updatedAt are converted to Amplication’s specialized UpdatedAt type. |
DateTime | DateTime | Plain DateTime fields remain as DateTime in Amplication. |
Float, Decimal | Decimal Number | Prisma’s Float and Decimal types are converted to Amplication’s Decimal Number type. |
Int, BigInt | WholeNumber | Prisma’s Int and BigInt types are converted to Amplication’s WholeNumber type. |
String | SingleLineText | Standard String fields are converted to Amplication’s SingleLineText type, suitable for short text inputs. |
Json | Json | Json types are directly equivalent. |
Enum | OptionSet | Prisma Enum types are converted to Amplication’s OptionSet, providing structured choice options. |
Enum[] | MultiSelectOptionSet | Prisma Enum[] arrays are converted to MultiSelectOptionSet, allowing multiple selections from options. |
| Model relation | Lookup | Relations to other models are converted to Amplication’s Lookup type, establishing entity relationships. |
Common Id Field Conversion Scenarios
The id field is central to Amplication’s entity model, and its conversion requires careful handling.
Here are common scenarios you might encounter:
Scenario 1: Existing @default Attribute on 'id' Field
Scenario 1: Existing @default Attribute on 'id' Field
If your
id field already has a @default attribute, Amplication removes it. This is because Amplication automatically adds a @default attribute that aligns with the id type (e.g., cuid() or autoincrement()) during conversion. Having multiple @default attributes is invalid in Prisma schema.Example:Scenario 2: Model Without a Suitable 'id' Field
Scenario 2: Model Without a Suitable 'id' Field
If a model lacks a field that can serve as the
id, Amplication proactively adds an id field. This ensures every entity in Amplication has a clearly defined primary identifier. The added id field is of type String and defaults to cuid() for generating unique IDs.Example:Scenario 3: Multiple Unique Fields, One Named 'id'
Scenario 3: Multiple Unique Fields, One Named 'id'
If multiple fields could potentially become the
id field (e.g., multiple @unique fields), and one of them is already named id, Amplication prioritizes the field named id. This field is then designated as the primary @id and configured with an appropriate @default attribute (like autoincrement() for Int types).Example:Scenario 4: No Unique Field Named 'id'
Scenario 4: No Unique Field Named 'id'
In cases where no unique field is named
id, Amplication selects a unique field (often the first one encountered) and renames it to id. To maintain database integrity, a @map attribute is added, mapping the new id field back to its original name in the database.Example:Log Warnings: Addressing Potential Issues
During schema processing, Amplication provides logs, including(Info) and (Warning) messages. While the schema will still process with warnings, it’s crucial to review them. Warnings indicate potential discrepancies or areas where the conversion might not perfectly align with your original schema’s intent. Addressing warnings proactively can prevent unexpected behavior in your generated services.
Custom Attributes on Enum Keys
Custom Attributes on Enum Keys
Amplication’s
OptionSet and MultiSelectOptionSet types handle Enums effectively. However, Amplication currently does not fully support custom attributes like @map or @@map directly on Enum keys or Enums themselves.If your Prisma schema uses these attributes on Enums, they will not be preserved in the converted schema.Impact: If your application logic relies heavily on these custom mapping attributes for Enums, you’ll need to manually adjust the generated schema.prisma or your application code to ensure correct behavior after importing into Amplication.Composite IDs on Models
Composite IDs on Models
As mentioned earlier, Amplication’s entity model primarily works with single-field IDs. If your Prisma schema uses composite IDs defined with
@@id([field1, field2, ...]), Amplication adapts this by:- Converting
@@idto@@uniqueto maintain database-level uniqueness constraints. - Adding a new, singular
idfield (String type,cuid()default) to the model to serve as Amplication’s primary identifier.
@@unique constraint, the shift from a composite ID to a singular id might require adjustments in how you design relationships and queries within Amplication. Be mindful of this change when working with entities that originally used composite IDs.Amplication logs warnings when it encounters models with @@id attributes and no existing id field, alerting you to this conversion.Conclusion
By understanding how Amplication converts your Prisma schema, you gain valuable insight into how Amplication helps you establish and maintain a standardized data model. Review the conversion logs after uploading your schema and explore your newly created entities in Amplication’s ERD view.Upload Your Schema
Learn how to upload your Prisma schema to Amplication and jumpstart your
service development.
Customize Your Entities
Discover how to further customize your entities and fields within
Amplication after schema import.